(原标题:未央本周回顾:央行连续下调7天期逆回购利率和MLF利率 多家股份制银行下调存款利率)
监管与市场聚焦
降息!央行7天期逆回购利率下调10个基点,MLF利率下调10个基点
为维护银行体系流动性合理充裕,6月13日人民银行以利率招标方式开展了20亿元逆回购操作,中标利率1.90%,下降10个基点。随后在6月15日,人民银行开展2370亿元中期借贷便利(MLF)操作,中标利率为2.65%,较前期下降10个基点。
一季度银行业消费投诉104909件
国家金融监督管理总局发布《关于2023年第一季度银行业消费投诉情况的通报》《关于2023年第一季度保险消费投诉情况的通报》。《通报》指出,监管部门2023年第一季度共接收并转送银行业消费投诉104909件。其中,涉及国有大型商业银行47219件,占投诉总量的45.0%;股份制商业银行29041件,占比27.7%;外资银行383件,占比0.4%;城市商业银行(含民营银行)15201件,占比14.5%;农村中小金融机构6500件,占比6.2%;其他银行业金融机构6565件,占比6.3%。监管部门2023年第一季度共接收并转送保险消费投诉26188件。其中,涉及财产保险公司11398件,占投诉总量的43.5%;人身保险公司14790件,占比56.5%。
市场监管总局发布盲盒经营行为规范指引 强化合规管理
中国市场监管总局发布盲盒经营行为规范指引,强化合规管理。法律法规明确规定禁止销售、流通的商品或者禁止提供的服务,不得以盲盒形式进行销售或者提供。药品、医疗器械、有毒有害物品、易燃易爆物品、活体动物等在使用条件、存储运输、检验检疫等方面有严格要求的商品,不得以盲盒形式销售。食品、化妆品,不具备保障质量安全和消费者权益条件的,不应当以盲盒形式销售。
两部门:2023—2025年拟分三批组织开展中小企业数字化转型城市试点工作
据财联社,财政部、工业和信息化部拟分三批组织开展中小企业数字化转型城市试点工作。2023年先选择30个左右城市开展试点工作,以后年度根据实施情况进一步扩大试点范围。各试点城市应将制造业关键领域的中小企业作为数字化转型试点的重点方向,重点向通用和专用设备制造、汽车制造、运输设备制造、医药和化学制造、电气机械和器材制造、计算机和通讯电子等行业中小企业倾斜。中央财政对试点城市给予定额奖励。其中,省会城市、计划单列市、兵团奖补资金总额不超过1.5亿元,其他地级市、直辖市所辖区县奖补资金总额不超过1亿元。
大公司动态
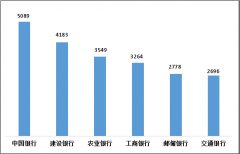
11家股份制银行下调存款利率 或为LPR下调提供“缓冲垫”
据证券日报,继6月8日国有六大行宣布下调存款利率后,6月12日,11家股份制银行也相继下调了部分期限存款利率。利率下调后,股份制银行活期存款挂牌利率降至0.2%,5年期定存利率最高为2.8%。
小米回应被印度没收48亿元
6月13日,根据媒体报道,印度执法局(ED)发布文件称,已正式向小米印度、该公司相关高管以及三家银行等发出通知,陈述其非法汇款555.1亿卢比资金(约合人民币48亿元)的行为。对此,小米相关人士对《每日经济新闻》称,对此事回应与此前一致:“小米在全球范围内坚持合法合规经营,并遵守经营地的相关法律法规。”
阿里云公布1+4开源战略
据36氪,2023开放原子全球开源峰会上,阿里云公布1+4开源战略,在操作系统、云原生、数据库、大数据四大开源领域之外,AI模型社区魔搭作为大模型方向的开源新势力首次亮相。目前已有15款支持中文的开源大模型在魔搭社区上线。
国际视角
欧盟立法机构通过里程碑式的人工智能法规
6月14日,欧洲议会以499票赞成、28票反对和93票弃权通过了其关于人工智能(AI)法案的谈判立场,并将在随后与欧盟成员国就该法律的最终形式进行谈判。这些规则将确保欧洲开发和使用的人工智能完全符合欧盟的权利和价值观,包括人类监督、安全、隐私、透明、非歧视以及社会和环境福祉。
日本数字银行服务平台Habitto开门营业
近日,总部位于东京的金融科技初创公司Habitto宣布开门营业。该公司已经注册为一家银行和证券中介平台,共有员工17名,其中包括3名金融顾问。其核心产品为Habitto账户,仅用于手机端储蓄服务,并附带一张Visa借记卡,其提供的0.3%的存款利率(面向首笔100万日元存款)也远高于传统银行提供的0.001%利率。用户还可以通过应用内聊天和视频通话服务,获得针对个性化理财计划的免费理财咨询服务。
本文系未央网专栏作者:未央研究 发表,内容属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!